Kafka Connect 시리즈 목차
- Kafka Connect: 소개와 아키텍처
- Kafka Connect: Debezium CDC 파이프라인 구축
- Kafka Connect: 모니터링과 장애 대응
코드 없이 데이터를 옮기는 방법
Kafka를 운영하다 보면 “DB에서 레코드를 읽어 토픽에 넣고, 토픽의 메시지를 검색 엔진에 적재하는” 파이프라인을 자주 만들게 된다. 처음에는 프로듀서/컨슈머 애플리케이션을 직접 작성하는 방식으로 해결하지만, 파이프라인 수가 늘어나면서 반복되는 문제가 드러난다.
오프셋 관리, 장애 복구, 스키마 변환, 병렬 처리 같은 로직은 파이프라인마다 거의 동일한데,
매번 새로 구현해야 한다. 코드 품질도 팀원마다 제각각이고, 운영 부담은 파이프라인 수에 비례해서 늘어난다.
프로듀서 하나를 제대로 튜닝하는 것만 해도 재시도, acks,
멱등성, 배치 설정의 조합을 신중히 결정해야 하는데, 이 과정을 수십 개 파이프라인에 반복하는 것은 비효율적이다.
Kafka Connect란
Kafka Connect는 Kafka 생태계에 포함된 설정 기반 데이터 파이프라인 프레임워크다. 프로듀서/컨슈머를 직접 작성하는 대신, JSON 설정 파일 하나로 “어디서 읽어 어디에 쓸지”를 정의하면 오프셋 추적, 장애 복구, 스케일 아웃 같은 공통 관심사는 프레임워크가 알아서 처리한다.
Kafka의 프로듀서와 컨슈머는 “어떻게 옮길지”를 코드로 짜는 클라이언트 라이브러리다. 오프셋 관리, 에러 처리, 직렬화를 개발자가 직접 구현한다. 반면 Kafka Connect는 “무엇을 어디로 옮길지”를 설정으로 선언하는 별도의 런타임이다. Kafka 브로커와 외부 시스템(데이터베이스, 검색 엔진, 클라우드 스토리지 등) 사이의 데이터 이동을 담당하며, 개발자가 파이프라인 로직이 아니라 데이터 흐름 자체에 집중할 수 있게 해 준다.
Kafka Connect 아키텍처
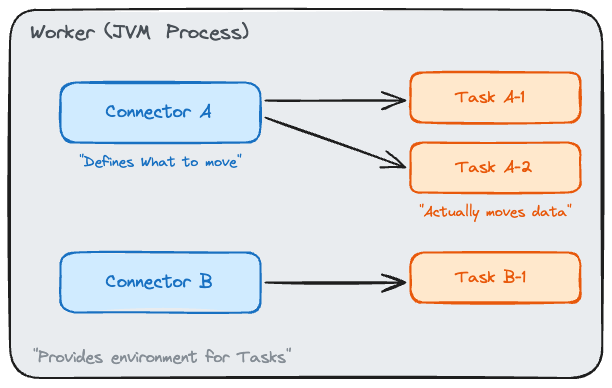
Connector, Task, Worker의 관계
Kafka Connect는 세 가지 핵심 요소로 구성된다.
Connector는 파이프라인의 논리적 단위다. “MySQL의 articles 테이블을 article-events 토픽에 적재한다”와 같은 작업을 하나의 Connector로 정의한다.
Connector 자체가 데이터를 복사하지는 않는다. 어떤 소스에서 어떤 싱크로, 어떤 변환을 거쳐 데이터를 옮길지 설정을 선언하는 역할이다.
Task는 실제 데이터 복사를 수행하는 실행 단위다. 하나의 Connector는 병렬 처리를 위해 여러 개의 Task를 생성할 수 있다.
예를 들어 MySQL 테이블 세 개를 동시에 읽어야 한다면 tasks.max=3으로 설정해 각 테이블을 별도 Task가 담당하게 할 수 있다.
Worker는 Task를 호스팅하는 JVM 프로세스다. 하나의 Worker 안에서 여러 Connector의 Task가 함께 실행된다. Worker가 여러 대라면 Task는 Worker 사이에 분산 배치된다.
정리하면 Connector가 “무엇을 옮길지” 정의하고, Task가 “실제로 옮기고”, Worker가 “Task를 실행하는 환경을 제공”한다.
Source Connector와 Sink Connector
Connector는 데이터 흐름 방향에 따라 두 종류로 나뉜다.
Source Connector는 외부 시스템에서 데이터를 읽어 Kafka 토픽에 적재한다.
MySQL의 articles 테이블을 주기적으로 읽어 article-events 토픽으로 보내는 파이프라인이 대표적인 예다.
Sink Connector는 반대 방향이다. Kafka 토픽의 메시지를 읽어 외부 시스템에 적재한다.
article-events 토픽의 메시지를 Elasticsearch에 인덱싱하면, 기사 검색 기능을 별도의 컨슈머 코드 없이 구성할 수 있다.
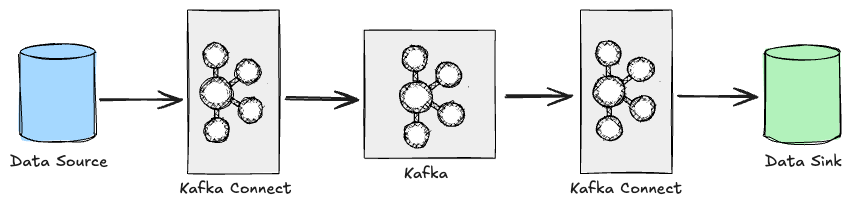
하나의 Kafka Connect 클러스터 안에서 Source와 Sink Connector를 함께 운영할 수 있으므로, “MySQL → Kafka → Elasticsearch”로 이어지는 전체 파이프라인을 Kafka Connect만으로 구성하는 것도 가능하다.
Converter와 SMT
Connector가 데이터를 토픽에 쓰거나 읽을 때, 직렬화와 역직렬화를 담당하는 것이 Converter다.
JsonConverter를 쓰면 메시지가 JSON으로 저장되고, AvroConverter를 쓰면 Schema Registry와 연동해 Avro 포맷으로 저장된다.
스키마 관리가 필요 없는 간단한 파이프라인이면 JsonConverter로 충분하고,
여러 팀이 같은 토픽을 소비하면서 스키마 호환성을 보장해야 한다면 AvroConverter가 적합하다.
SMT(Single Message Transform)는 메시지가 Connector를 통과하는 도중에 적용되는 경량 변환이다. 특정 필드를 제거하거나, 타임스탬프 포맷을 변환하거나, 토픽 라우팅을 변경하는 등의 작업을 Connector 설정만으로 처리할 수 있다.
{
// 적용할 SMT 이름을 쉼표로 나열한다. 순서대로 실행된다.
"transforms": "dropField,routeByStatus",
// dropField: internal_id 필드를 메시지에서 제거한다
"transforms.dropField.type": "org.apache.kafka.connect.transforms.ReplaceField$Value",
"transforms.dropField.exclude": "internal_id",
// routeByStatus: 토픽 이름을 정규식으로 치환한다
"transforms.routeByStatus.type": "org.apache.kafka.connect.transforms.RegexRouter",
"transforms.routeByStatus.regex": "article-events",
"transforms.routeByStatus.replacement": "article-events-v2"
}
다만 SMT는 메시지 하나 단위로 동작하므로, 여러 메시지를 조인하거나 집계하는 복잡한 변환에는 적합하지 않다. 그런 경우에는 Kafka Streams나 별도의 스트림 처리 프레임워크를 고려하는 편이 낫다.
Standalone 모드와 Distributed 모드
Kafka Connect Worker는 두 가지 모드로 실행할 수 있다. 어떤 모드를 선택하느냐에 따라 확장성, 장애 복구, 운영 방식이 크게 달라진다.
Standalone 모드는 언제 쓸까?
Standalone 모드는 단일 Worker 프로세스에서 모든 Connector와 Task를 실행한다. 설정 파일을 프로퍼티 파일로 전달하고, 오프셋 정보도 로컬 파일에 저장한다. 구조가 단순해서 로컬 개발이나 테스트 환경에서 빠르게 파이프라인을 검증할 때 유용하다.
# connect-standalone.sh: Standalone 모드 실행 스크립트
# 첫 번째 인자: Worker 공통 설정 (bootstrap.servers, key/value converter 등)
# 이후 인자: 실행할 Connector 설정 파일들 (여러 개 가능)
connect-standalone.sh worker.properties connector-a.properties connector-b.properties
단일 프로세스이므로 Worker가 죽으면 전체 파이프라인이 멈추고, 수평 확장도 불가능하다. 로그 수집 에이전트처럼 단일 노드에서 동작하는 단순한 시나리오가 아니라면 프로덕션에서는 권장하기 어렵다.
Distributed 모드가 운영 환경에서 권장되는 이유
Distributed 모드에서는 여러 Worker가 하나의 Connect 클러스터를 구성하고, Task를 Worker 사이에 분산 배치한다. Worker 하나가 장애로 탈락하면 해당 Worker의 Task가 나머지 Worker로 자동 재배치(rebalance)된다.
Standalone 모드와 가장 큰 차이점은 상태 저장 방식이다.
오프셋, Connector 설정, Task 상태를 로컬 파일이 아니라 Kafka 내부 토픽(connect-offsets, connect-configs, connect-status)에 저장한다.
Kafka 토픽 설정을 다룬 글에서 본 것처럼 내부 토픽도 파티션 수와 복제 팩터를 적절히 설정해야
Distributed 모드의 안정성을 확보할 수 있다.
Connector 관리도 다르다. 프로퍼티 파일 대신 REST API를 통해 Connector를 등록, 수정, 삭제한다.
# Connector 등록: POST 요청으로 Connector 이름과 설정을 전달한다
curl -X POST http://localhost:8083/connectors \
-H "Content-Type: application/json" \
-d '{
"name": "article-source",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://mysql-host:3306/news",
"connection.user": "connect_user",
"connection.password": "****",
"table.include.list": "articles", // 읽어올 테이블
"mode": "incrementing", // 증가하는 컬럼 기반으로 변경분 추적
"incrementing.column.name": "id", // 증가 기준 컬럼
"topic.prefix": "article-events-", // 생성되는 토픽의 접두사
"poll.interval.ms": "5000" // 폴링 간격 (기본값 5초)
}
}'
등록한 Connector의 상태는 별도 엔드포인트로 확인한다.
# Connector 상태 확인
curl http://localhost:8083/connectors/article-source/status
{
"name": "article-source",
"connector": {
"state": "RUNNING",
"worker_id": "localhost:8083"
},
"tasks": [
{
"id": 0,
"state": "RUNNING",
"worker_id": "localhost:8083"
}
]
}
REST API에 인증 없이 접근 가능한 환경이라면 누구나 Connector를 등록/삭제할 수 있으므로, 프로덕션 환경에서는 네트워크 접근 제어나 별도의 인증 플러그인 적용을 반드시 검토해야 한다.
아래 표는 두 모드의 주요 차이를 정리한 것이다.
| 항목 | Standalone | Distributed |
|---|---|---|
| 확장성 | 단일 Worker, 수평 확장 불가 | 여러 Worker로 수평 확장 |
| 장애 복구 | Worker 죽으면 파이프라인 중단 | Task 자동 재배치(rebalance) |
| 오프셋 저장 | 로컬 파일 | Kafka 내부 토픽 |
| 설정 방식 | 프로퍼티 파일 | REST API |
| 용도 | 로컬 테스트, 단순 에이전트 | 프로덕션 운영 |
돌아보며
Kafka Connect의 핵심은 “반복되는 데이터 파이프라인을 코드가 아닌 설정으로 관리한다”는 점에 있다. Connector, Task, Worker라는 역할 분리와 Distributed 모드의 자동 재배치 덕분에, 파이프라인 수가 늘어나도 운영 복잡도가 비례해서 증가하지 않는다.
물론 모든 상황에 Kafka Connect가 정답은 아니다. 메시지를 변환하는 과정에서 복잡한 비즈니스 로직이 필요하거나, 외부 시스템과의 상호작용이 단순 적재를 넘어서는 경우에는 프로듀서/컨슈머를 직접 구현하는 편이 유연하다. Kafka Connect가 맞지 않는 상황을 미리 알아두면, 맞는 상황에서 더 잘 쓸 수 있지 않을까 싶다.
끝으로, 이 글에서는 JDBC Source Connector를 예시로 들었는데, 폴링 방식에는 DELETE를 감지하지 못하는 등의 한계가 있다. 다음 글에서는 데이터베이스의 트랜잭션 로그를 직접 읽어 이 한계를 넘는 Debezium CDC 파이프라인을 다룬다.