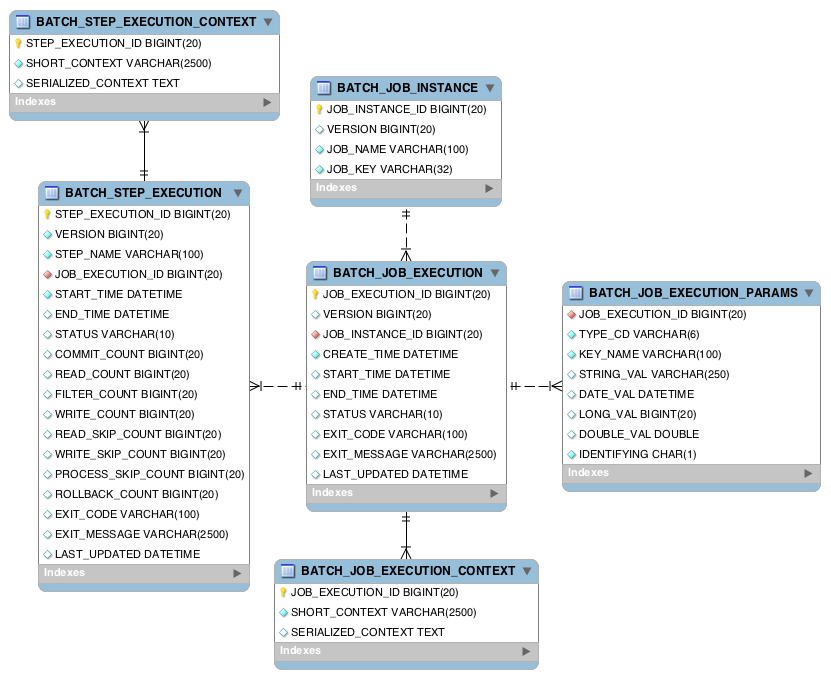
Spring Batch Meta-Data Tables
In Spring Batch, each run records Job/Step status and history. So, metadata tables are required to run Spring Batch.
Metadata Table DDL Scripts
Spring Batch includes SQL scripts for metadata table creation.
In Spring Batch Core 4.3.7, you can find multiple SQL files under org.springframework.batch.core.
For example, in MySQL, schema-mysql.sql contains table creation statements like the following.
-- Autogenerated: do not edit this file
CREATE TABLE BATCH_JOB_INSTANCE (
JOB_INSTANCE_ID BIGINT NOT NULL PRIMARY KEY ,
VERSION BIGINT ,
JOB_NAME VARCHAR(100) NOT NULL,
JOB_KEY VARCHAR(32) NOT NULL,
constraint JOB_INST_UN unique (JOB_NAME, JOB_KEY)
) ENGINE=InnoDB;
CREATE TABLE BATCH_JOB_EXECUTION (
JOB_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY ,
VERSION BIGINT ,
JOB_INSTANCE_ID BIGINT NOT NULL,
CREATE_TIME DATETIME(6) NOT NULL,
START_TIME DATETIME(6) DEFAULT NULL ,
END_TIME DATETIME(6) DEFAULT NULL ,
STATUS VARCHAR(10) ,
EXIT_CODE VARCHAR(2500) ,
EXIT_MESSAGE VARCHAR(2500) ,
LAST_UPDATED DATETIME(6),
JOB_CONFIGURATION_LOCATION VARCHAR(2500) NULL,
constraint JOB_INST_EXEC_FK foreign key (JOB_INSTANCE_ID)
references BATCH_JOB_INSTANCE(JOB_INSTANCE_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_JOB_EXECUTION_PARAMS (
JOB_EXECUTION_ID BIGINT NOT NULL ,
TYPE_CD VARCHAR(6) NOT NULL ,
KEY_NAME VARCHAR(100) NOT NULL ,
STRING_VAL VARCHAR(250) ,
DATE_VAL DATETIME(6) DEFAULT NULL ,
LONG_VAL BIGINT ,
DOUBLE_VAL DOUBLE PRECISION ,
IDENTIFYING CHAR(1) NOT NULL ,
constraint JOB_EXEC_PARAMS_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_STEP_EXECUTION (
STEP_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY ,
VERSION BIGINT NOT NULL,
STEP_NAME VARCHAR(100) NOT NULL,
JOB_EXECUTION_ID BIGINT NOT NULL,
START_TIME DATETIME(6) NOT NULL ,
END_TIME DATETIME(6) DEFAULT NULL ,
STATUS VARCHAR(10) ,
COMMIT_COUNT BIGINT ,
READ_COUNT BIGINT ,
FILTER_COUNT BIGINT ,
WRITE_COUNT BIGINT ,
READ_SKIP_COUNT BIGINT ,
WRITE_SKIP_COUNT BIGINT ,
PROCESS_SKIP_COUNT BIGINT ,
ROLLBACK_COUNT BIGINT ,
EXIT_CODE VARCHAR(2500) ,
EXIT_MESSAGE VARCHAR(2500) ,
LAST_UPDATED DATETIME(6),
constraint JOB_EXEC_STEP_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_STEP_EXECUTION_CONTEXT (
STEP_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT TEXT ,
constraint STEP_EXEC_CTX_FK foreign key (STEP_EXECUTION_ID)
references BATCH_STEP_EXECUTION(STEP_EXECUTION_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_JOB_EXECUTION_CONTEXT (
JOB_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT TEXT ,
constraint JOB_EXEC_CTX_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_STEP_EXECUTION_SEQ (
ID BIGINT NOT NULL,
UNIQUE_KEY CHAR(1) NOT NULL,
constraint UNIQUE_KEY_UN unique (UNIQUE_KEY)
) ENGINE=InnoDB;
INSERT INTO BATCH_STEP_EXECUTION_SEQ (ID, UNIQUE_KEY) select * from (select 0 as ID, '0' as UNIQUE_KEY) as tmp where not exists(select * from BATCH_STEP_EXECUTION_SEQ);
CREATE TABLE BATCH_JOB_EXECUTION_SEQ (
ID BIGINT NOT NULL,
UNIQUE_KEY CHAR(1) NOT NULL,
constraint UNIQUE_KEY_UN unique (UNIQUE_KEY)
) ENGINE=InnoDB;
INSERT INTO BATCH_JOB_EXECUTION_SEQ (ID, UNIQUE_KEY) select * from (select 0 as ID, '0' as UNIQUE_KEY) as tmp where not exists(select * from BATCH_JOB_EXECUTION_SEQ);
CREATE TABLE BATCH_JOB_SEQ (
ID BIGINT NOT NULL,
UNIQUE_KEY CHAR(1) NOT NULL,
constraint UNIQUE_KEY_UN unique (UNIQUE_KEY)
) ENGINE=InnoDB;
INSERT INTO BATCH_JOB_SEQ (ID, UNIQUE_KEY) select * from (select 0 as ID, '0' as UNIQUE_KEY) as tmp where not exists(select * from BATCH_JOB_SEQ);
For reference, MySQL does not support sequences, so schema-mysql.sql includes statements like this:
CREATE TABLE BATCH_STEP_EXECUTION_SEQ (ID BIGINT NOT NULL) type=InnoDB;
INSERT INTO BATCH_STEP_EXECUTION_SEQ values(0);
CREATE TABLE BATCH_JOB_EXECUTION_SEQ (ID BIGINT NOT NULL) type=InnoDB;
INSERT INTO BATCH_JOB_EXECUTION_SEQ values(0);
CREATE TABLE BATCH_JOB_SEQ (ID BIGINT NOT NULL) type=InnoDB;
INSERT INTO BATCH_JOB_SEQ values(0);
Can This Be Auto-Created?
Yes. Spring Batch metadata tables can be auto-created by configuration.
In Spring Boot 2.7.0, set spring.batch.jdbc.initialize-schema to always in application.yml.
When set, table creation scripts run at application startup and metadata tables are created automatically.
spring:
batch:
jdbc:
initialize-schema: always
Additional values are embedded and never.
The default embedded creates metadata tables only for embedded databases.
never disables creation. So, if you do not want auto-creation at first startup, set it to never.
Also note that spring.batch.initialize-schema used in older versions is removed in 2.7.0.
In older source, you can see the @Deprecated annotation below.
@Deprecated
@DeprecatedConfigurationProperty(replacement = "spring.batch.jdbc.initialize-schema")
public DataSourceInitializationMode getInitializeSchema() {
return this.jdbc.getInitializeSchema();
}
Table Creation Flow
If you inspect the execution flow, schema locations are resolved during BatchDataSourceScriptDatabaseInitializer bean initialization.
public class BatchDataSourceScriptDatabaseInitializer extends DataSourceScriptDatabaseInitializer {
public BatchDataSourceScriptDatabaseInitializer(DataSource dataSource, BatchProperties.Jdbc properties) {
this(dataSource, getSettings(dataSource, properties));
}
public static DatabaseInitializationSettings getSettings(DataSource dataSource, BatchProperties.Jdbc properties) {
DatabaseInitializationSettings settings = new DatabaseInitializationSettings();
// resolve schema locations
settings.setSchemaLocations(resolveSchemaLocations(dataSource, properties));
// ALWAYS, EMBEDDED, NEVER
settings.setMode(properties.getInitializeSchema());
// continue initialization even when errors occur
settings.setContinueOnError(true);
return settings;
}
// ...
}
Then afterPropertiesSet in AbstractScriptDatabaseInitializer (which is a superclass of DataSourceScriptDatabaseInitializer) executes scripts.
public abstract class AbstractScriptDatabaseInitializer implements ResourceLoaderAware, InitializingBean {
@Override
public void afterPropertiesSet() throws Exception {
initializeDatabase();
}
public boolean initializeDatabase() {
ScriptLocationResolver locationResolver = new ScriptLocationResolver(this.resourceLoader);
boolean initialized = applySchemaScripts(locationResolver);
return applyDataScripts(locationResolver) || initialized;
}
// ...
}
public class DataSourceScriptDatabaseInitializer extends AbstractScriptDatabaseInitializer {
@Override
protected void runScripts(List<Resource> resources, boolean continueOnError, String separator, Charset encoding) {
ResourceDatabasePopulator populator = new ResourceDatabasePopulator();
populator.setContinueOnError(continueOnError);
populator.setSeparator(separator);
if (encoding != null) {
populator.setSqlScriptEncoding(encoding.name());
}
for (Resource resource : resources) {
populator.addScript(resource);
}
customize(populator);
DatabasePopulatorUtils.execute(populator, this.dataSource); // internally executes SQL scripts
}
// ...
}
The snippet below is part of ScriptUtils.executeSqlScript, where scripts are actually executed.
Because setContinueOnError is set to true earlier, initialization does not stop even when exceptions occur.
try {
// ...
} catch (SQLException ex) {
boolean dropStatement = StringUtils.startsWithIgnoreCase(statement.trim(), "drop");
if (continueOnError || (dropStatement && ignoreFailedDrops)) {
if (logger.isDebugEnabled()) {
logger.debug(ScriptStatementFailedException.buildErrorMessage(statement, stmtNumber, resource), ex);
}
}
else {
throw new ScriptStatementFailedException(statement, stmtNumber, resource, ex);
}
}
So, when spring.batch.jdbc.initialize-schema is set to always, startup does not fail even if metadata tables already exist,
as shown below.