Spring JDBC
자바에서 제공하는 JDBC(Java Database Connectivity)를 사용할 때는 커넥션 연결, 예외 처리, 트랜잭션 등, 수많은 반복적으로 등장하는 코드를 개발자가 직접 작성하고 관리해야 하는 불편함이 있다. Spring JDBC는 이러한 저 수준(Low-level) 처리를 스프링 프레임워크가 직접 해줌으로써 JDBC가 가진 단점을 극복할 수 있게 해준다.
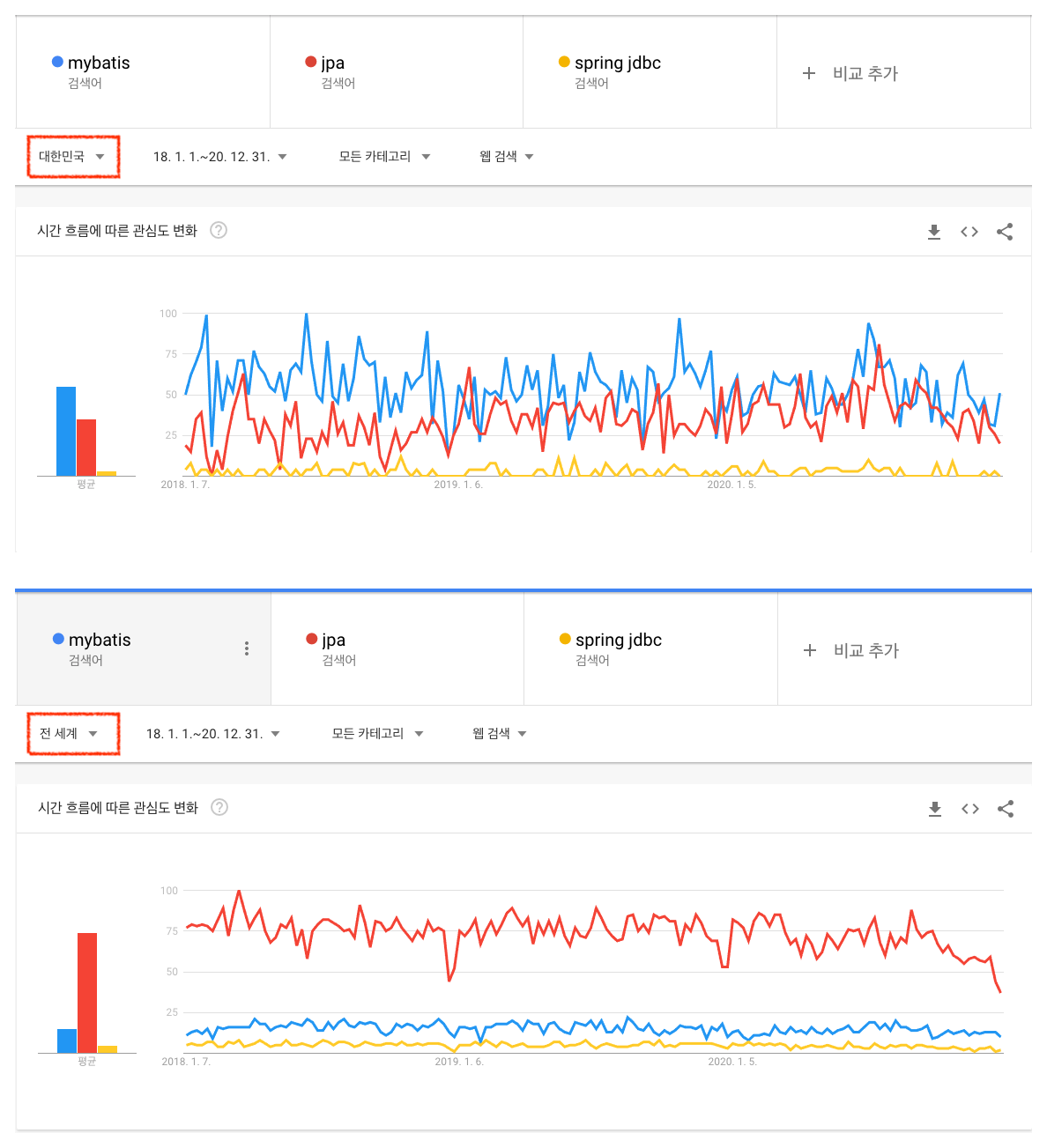
그런데 2021년인 지금, Spring JDBC를 사용하는 프로젝트를 찾기 어렵다. 이는 구글 트렌트만 보아도 그렇다. 세계적인 트렌드뿐만 아니라 우리나라의 트렌드만 보아도 MyBatis나 JPA(Java Persistent API) 사용이 압도적이다.
Bulk Insert 강자
그렇다고 Spring JDBC가 기능적으로 부족하기만 한 것은 아니다. Spring JDBC는 SQL Mapper나 ORM의 사용법을 모르더라도 SQL만 알면 사용할 수 있으며, 사용하기 위한 설정도 매우 단순하기 때문에 학습 비용이 낮은 장점이 있다.
실제로 배치와 같은 컴포넌트에서의 대량 데이터 삽입(bulk insert) 성능은 Spring JDBC가 제일 우수했다. 1만 건의 데이터를 기준으로 MyBatis 보다 2배 이상 빨랐으며, 이 차이는 데이터의 개수가 많을수록 더 커졌다.
성능 측정에서 DB는 MySQL를 사용했으며,
rewriteBatchedStatements옵션을 true로 설정했다. 이 옵션을 설정하지 않은 경우 MyBatis 보다 bulk insert 성능이 비슷하거나 조금 빠른 수준이었다.
이러한 성능상 이점으로 인해 아직도 몇몇 프로젝트에서는 Spring JDBC를 유지하고 있다. 오히려 단순히 쿼리 실행만을 필요로 한다면 다른 프레임워크보다 Spring JDBC가 더 좋은 선택일 수도 있다.
가독성/생산성 저하
그런데 Spring JDBC를 사용할 때마다 항상 느끼는 불편함이 있다. 바로 자바 코드와 한데 섞이는 SQL 문이다. 아래는 간단한 예시지만, 다른 테이블과 조인(join) 하는 등의 복잡한 쿼리가 작성된다면 가독성이 매우 좋지 않을 것이다.
public List<Article> getArticleList(String id) {
Map<String, Object> params = new HashMap<>();
params.put("id", id);
// Mapper 정의는 생략
return jdbcTemplate.queryForList(
"SELECT " +
" id, title, content, author " +
"FROM " +
" article " +
"WHERE " +
" id = :id", params, new ArticleMapper());
}
특히나 Workbench나 Sequel Pro 같은 SQL 툴을 통해서 SQL 문을 테스트할 때는 쿼리를 감싸고 있는 큰따옴표를 제거하는 작업을 매번 번거롭게 해야 한다. 생산성 향상은커녕 따옴표 제거와 씨름하고 있는 자신을 발견할지도 모른다.
JEP 368: Text Blocks
아예 방법이 없는 것은 아니다. 자바 13에서는 두 번째 Preview 스펙으로 등장한 Text Blocks라는 기능이 있다.
텍스트 블록을 사용하면 위에서 살펴본 Spring JDBC 예시처럼 긴 문자열을 +를 사용하여 이어붙이지 않아도 된다.
public List<Article> getArticleList(String id) {
Map<String, Object> params = new HashMap<>();
params.put("id", id);
// Mapper 정의는 생략
return jdbcTemplate.queryForList(
"""
SELECT
id, title, content, author
FROM
article
WHERE
id = :id
""", params, new ArticleMapper());
}
하지만 프로젝트 특성상, 회사 내규상 등등 여러 이유로 13버전 이상의 JDK를 사용하지 못할 수 있다. 대부분 LTS(Long Term Support) 버전을 사용할 텐데, 가장 최근의 LTS 버전은 텍스트 블록이 없는 자바 11 버전이다. 그렇다면 이럴 때는 어떻게 해야 할까?
방법 1: Spring Properties
스프링 프레임워크이 Properties 설정을 활용하는 방법이 있다. SQL 문을 XML 파일로 옮기고 코드 레벨에서 설정을 통해 불러와서 사용하면 된다.
먼저 아래와 같이 SQL 문을 XML 파일에 정의하고,
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd" >
<properties>
<entry key="article.selectArticleList">
SELECT
id, title, content, author
FROM
article
WHERE
id = :id
</entry>
</properties>
아래와 같이 자바 코드에서 사용하면 된다.
@Repository
@PropertSource("classpath:sqlmap/article.xml")
public class ArticleRepository {
private NamedParameterJdbcTemplate namedJdbcTemplate;
@Value("${article.selectArticleList}")
private String selectArticleListQuery;
public List<Article> getArticleList(String id) {
Map<String, Object> params = new HashMap<>();
params.put("id", id);
return namedJdbcTemplate.queryForList(
selectArticleListQuery, params, new ArticleMapper());
}
}
SQL 문을 비즈니스 로직과 분리하긴 했지만, 쿼리 개수만큼 멤버 필드가 생긴다면 이 또한 꽤 보기 싫을 것이다.
방법 2: Kotlin Package-level 함수
JVM 기반 언어인 코틀린에서는 기본적으로 멀티 라인 문자열을 제공한다. 몇 가지 Gradle 설정을 추가하면 코틀린 기능을 사용할 수 있다.
apply plugin: 'kotlin'
buildscript {
ext {
kotlinVersion = '1.5.0'
}
repositories {
jcenter()
}
dependencies {
classpath("org.jetbrains.kotlin:kotlin-gradle-plugin:${kotlinVersion}")
}
}
dependencies {
implementation "org.jetbrains.kotlin:kotlin-stdlib:${kotlinVersion}"
}
SQL 문은 아래와 같이 코틀린 파일(.kt)에 작성하면 된다.
// article.kt
fun selectArticleListQuery() = """
SELECT
id, title, content, author
FROM
article
WHERE
id = :id
"""
자바 코드에서는 아래와 같이 사용하면 된다. 마치 전역 함수처럼 접근해서 사용하면 된다. 코틀린 파일의 이름이 Article이라면, ArticleKt로 접근된다.
@Repository
public class ArticleRepository {
private NamedParameterJdbcTemplate namedJdbcTemplate;
public List<Article> getArticleList(String id) {
Map<String, Object> params = new HashMap<>();
params.put("id", id);
return namedJdbcTemplate.queryForList(
ArticleKt.selectArticleListQuery(), params, new ArticleMapper());
}
}
앞서 살펴본 XML 파일로 SQL 문을 분리하는 것보다 더 좋아 보인다. 하지만 또 다른 방법을 찾아보았다.
방법 3: Groovy
마지막으로 Groovy를 적용해보는 방법이 있다. 동일하게 Gradle 설정이 필요하지만 코틀린에 비해 상대적으로 적은 양이다.
apply plugin: 'groovy'
sourceSets {
main {
java { srcDirs = [] }
groovy { srcDirs += ['src/main/java'] }
}
}
dependencies {
implementation 'org.codehaus.groovy:groovy-all:3.0.8'
}
SQL 문은 그루비 파일(.groovy)에 작성한다.
class ArticleSql {
public static final String SELECT_ARTICLE_LIST = """
SELECT
id, title, content, author
FROM
article
WHERE
id = :id
"""
}
자바 코드는 아래와 같이 작성한다. 앞서 살펴본 코틀린과 매우 유사하지만 코틀린과 다르게 SQL 변수에 접근할 때는 선언한 클래스 이름으로 접근하면 된다.
@Repository
public class ArticleRepository {
private NamedParameterJdbcTemplate namedJdbcTemplate;
public List<Article> getArticleList(String id) {
Map<String, Object> params = new HashMap<>();
params.put("id", id);
return namedJdbcTemplate.queryForList(
ArticleSql.SELECT_ARTICLE_LIST, params, new ArticleMapper());
}
}
마치며
위에서 살펴본 세 가지 방법 모두 SQL 문과 비즈니스 로직을 분리하는 목적을 달성하지만 개인적으로는 마지막에 살펴본 Groovy를 사용하는 방법이 제일 좋은 것 같다.
Gradle 설정도 코틀린에 비해 간단했고 자바 문법을 계승했기 때문에 거부감이 적었다. 그래도 13버전 이상의 자바 버전을 사용하여 다른 설정 없이 멀티라인 문자열(multi-line string)을 사용하는 것이 가장 좋은 방법인 것 같다. 2021년 10월에 새로운 LTS 버전인 자바 16버전이 공개되면 이러한 설정 없이도 편하게 사용하게 되는 날이 오지 않을까 싶다.