동기화? 그것은 무엇일까?
동기화(Synchronization)는 작업들 사이의 수행 시기를 맞추는 것을 말합니다. 자바에서 List, Set 그리고 Map과 같은 컬렉션(Collection)의 구현 클래스를 사용할 때 바로 이 동기화가 중요한 이슈가 될 수 있는데요. 동기화가 제공되는 것이 무조건적으로 좋은 것이 아니라 실행 속도 측면에서 성능의 차이가 있기 때문에 상황에 따라서 적절하게 사용하는 것이 좋습니다.
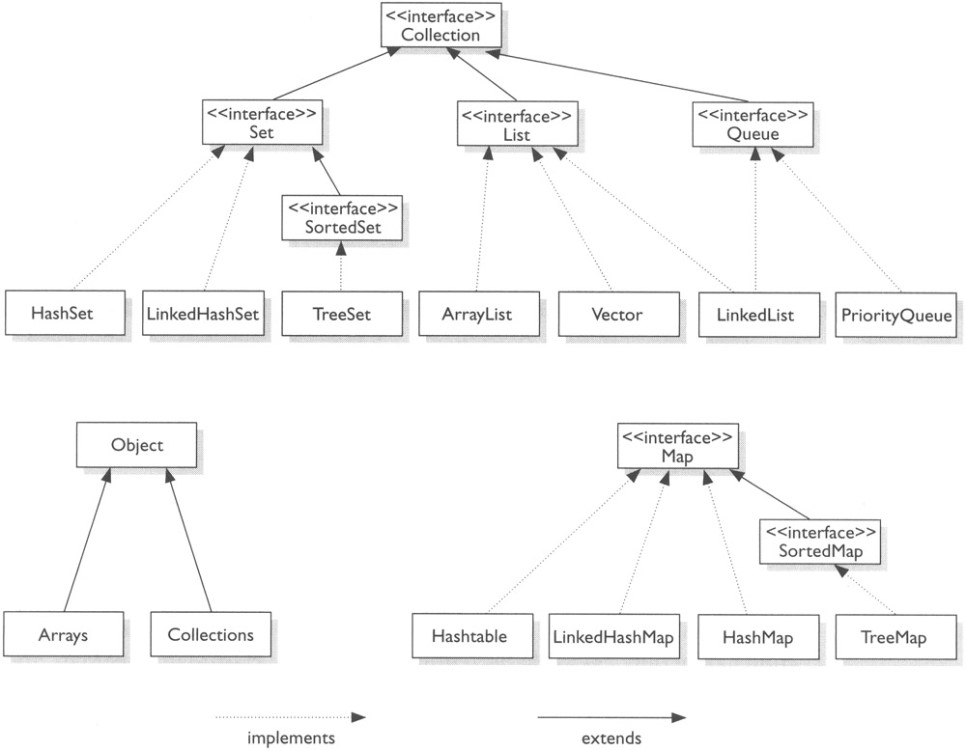
위의 그림처럼 자바에서는 수많은 Collection 인터페이스의 구현 클래스를 제공하고 있습니다. 너무 많으니까 대표적으로 List, Set 그리고 Map에 대해 살펴보도록 합시다.
리스트(List)
리스트는 자체적으로 순서가 있는 구성이며 리스트에 추가되는 요소(Element)의 중복을 허용합니다. 위의 그림에서 보면 알수있듯이 List 인터페이스를 구현하는 클래스는 ArrayList, Vector 그리고 LinkedList가 있습니다.
먼저 ArrayList에 대해서 살펴봅시다.
이클립스(Eclipse)나 인텔리제이(Intellij)와 같은 IDE 도구에서 ArrayList 클래스의 내부 구현코드로 진입하면
아래와 같은 코드를 볼 수 있습니다.
package java.util;
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
...
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
...
}
ArrayList 클래스는 동기화를 제공하지 않습니다.
위의 요소를 추가하는 add 메서드를 살펴보면 알 수 있듯이 동기화를 위한 코드가 보이지 않습니다.
다음으로 Vector를 살펴봅시다.
package java.util;
public class Vector<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
...
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
...
}
코드만 봐도 확실한 차이가 보이지요? Vector 클래스에서는 요소를 추가하는 add 메서드에서 자바에서 제공하는
synchronized 키워드가 보입니다. 즉, 내부적으로 Vector에서 요소 삽입 연산이 진행될 때 동기화가 보장된다는 것입니다.
먼저 살펴본 ArrayList 클래스도 동기화가 필요하다면 아래와 같이 코드를 변경하면 됩니다.
/*
* ArrayList Synchronization
*
* https://docs.oracle.com/javase/6/docs/api/java/util/Collections.html#synchronizedList(java.util.List)
* @author kimtaeng
*/
public void SomeMethod() {
List<String> synchronizedList = Collections.synchronizedList(new ArrayList<String>());
synchronizedList.add("MadPlay");
synchronizedList.add("MadPlay");
synchronizedList.add("Kimtaeng");
synchronized(synchronizedList) {
Iterator i = synchronizedList.iterator(); // Must be in synchronized block
while (i.hasNext()) {
foo(i.next());
}
}
}
ArrayList와 Vector외에 LinkedList도 있습니다.
데이터의 노드가 연겨되어 순서대로 늘어져 있는 구조이기 때문에 노드와 노드 사이에 값을 추가하거나
삭제할 때 연결된 링크값만 바꾸면 되므로 연산에 대한 성능이 상대적으로 빠릅니다.
앞서 살펴본 ArrayList와 Vector의 경우 요소의 위치 정보인 인덱스(Index)를 갖기 때문에 특정 위치에 대한 접근이 가능한 장점이 있지만 데이터의 추가를 진행할 때는 내부적으로 임시 배열을 생성한 후 복사하는 방법을 사용하기 때문에 대량의 요소를 추가하는 연산을 수행하는 경우 성능 저하가 발생합니다.
집합(Set)
집합(Set)은 순서를 유지하지 않는 데이터들의 집합이며, 먼저 살펴본 리스트(List)와는 다르게 요소들의 중복을 허용하지 않습니다. 대표적으로는 HashSet과 TreeSet 클래스가 있습니다.
HashSet 클래스를 살펴보면 ArrayList와 마찬가지로 동기화를 제공하지 않습니다. 또한 추가되는 요소들의 순서도 보장하지 않습니다. 의미가 없다는 말이 더 맞는 표현같기도 합니다.
Set에 추가되는 요소의 순서를 부여하기 위해서는 JDK 1.4 버전부터 도입된 LinkedHashSet이 있습니다. 이 클래스의 생성자를 살펴보면 HashSet 클래스와는 조금 다른 것을 알 수 있습니다.
/* LinkedHashSet Class */
public class LinkedHashSet<E> extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
...
public LinkedHashSet() {
super(16, .75f, true);
}
...
}
/* 여기서 부모 클래스의 생성인 super, 즉 HashSet의 오버로딩 생성자로 진입해보면 */
public class HashSet<E> extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
...
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
...
}
그러니까 LinkedHashSet은 상위 클래스인 HashSet을 만들고 내부적으로는 LinkedHashMap을 만들고 있는 모습입니다. TreeSet의 경우는 정렬 방법을 지정하여 순서대로 저장할 수 있습니다.
import java.util.Comparator;
import java.util.Iterator;
import java.util.TreeSet;
/**
* TreeSet 예제
*
* @author kimtaeng
* created on 2018. 4. 16.
*/
class MadPlay {
public void collectionTest() {
/* 오름차순으로 정렬하는 TreeSet */
TreeSet<Integer> treeSet = new TreeSet<Integer>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o1 > o2 ? 1 : (o1 == o2 ? 0 : -1);
}
});
treeSet.add(3); treeSet.add(1); treeSet.add(2);
Iterator<Integer> iterator = treeSet.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
/* using Java 8 */
TreeSet<Integer> java8TreeSet = new TreeSet<>(
(o1, o2) -> o1 > o2 ? 1 : (o1 == o2 ? 0 : -1)
);
java8TreeSet.add(3); java8TreeSet.add(1); java8TreeSet.add(2);
java8TreeSet.forEach(element -> {
System.out.println(element);
});
}
}
위 코드의 출력은 입력된 <3, 1, 2> 의 순서와 다르게 정렬된 <1, 2, 3>의 순서로 출력됩니다.
추가적으로 동기화를 제공하지 않는 Set은 앞서 살펴본 SynchronizedList처럼 변환할 수 있습니다.
/**
* TreeSet to SynchronizedSet
*
* @author kimtaeng
* created on 2018. 4. 16.
*/
public class MadPlay {
public void collectionTest() {
...
/* synchronizedSet */
Set<Integer> synchronizedSet = Collections.synchronizedSet(treeSet);
...
}
}
맵(Map)
Map은 Key와 Value의 쌍으로 이루어진 데이터를 저장합니다. HashMap, TreeMap, Hashtable 클래스 등이 있고 순서를 보장하는 LinkedHashMap도 있습니다.
먼저 살펴볼 것은 HashMap 입니다. 중복을 허용하지 않고 순서도 보장하지 않습니다.
Key 또는 Value의 값으로 null을 허용하는 특징이 있습니다.
TreeMap은 HashMap과 마찬가지로 중복을 허용하지 않지만 내부적으로 SortedMap을 구현하고 있기 때문에 Key 값들에 대해서 정렬이 이루어집니다.
/* TreeMap Class */
public class TreeMap<K,V> extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable {
...
}
/* NavigableMap Interface */
public interface NavigableMap<K,V> extends SortedMap<K,V> {
...
}
내부적으로 정렬을 진행하기 때문에 값을 추가할 때 상대적으로 시간이 더 소요됩니다. 앞서 살펴본 TreeSet과 마찬가지로 Comparator를 직접 구현하여 정렬 순서를 지정할 수도 있습니다.
public void someMethod() {
TreeMap<Integer, Integer> treeMap = new TreeMap<>(
(o1, o2) -> o1 > o2 ? 1 : (o1 == o2 ? 0 : -1)
);
}
마지막으로 Hashtable은 마찬가지로 중복을 허용하지 않지만 HashMap과는 다르게 Key와 Value의 값으로
null을 허용하지 않는 특징을 가지고 있습니다. HashMap보다는 느리지만 동기화를 제공 하지요.
/* Hashtable Class */
public class Hashtable<K,V> extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable {
public synchronized V get(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return (V)e.value;
}
}
return null;
}
}
동기화를 제공하지 않는 HashMap의 경우 KeySet을 순회하다가 새로운 값이 추가되는 경우에 이슈가 생기겠지만 동기화를 지원하는 컬렉션은 이러한 경우에 문제가 되지 않겠죠?
Map의 경우에도 동기화 기능을 위해 Collections.SynchroniezdMap 메서드를 사용할 수 있지만 이번에는 조금 다른 방법을 소개하려고 합니다.
Concurrent
Java 1.5 버전부터 등장한 java.util.concurrent 패키지는 다양한 동시성 기능을 제공합니다.
Java 1.5 API Docs
HashMap에 동기화 기능을 적용한 ConcurrentHashMap 이 여기에 속해있습니다.
동기화를 위해서 SynchronizedMap을 사용할 수 있지만 지금 살펴볼 ConcurrentHashMap의 성능이 더 좋습니다
이유는 바로 동기화 블록 범위(Scope)에 있는데요. ConcurrentHashMap은 동기화를 진행하는 경우 Map 전체에 락(Lock)을 걸지 않고 Map을 여러 조각으로 나누어서 부분적으로 락을 거는 형태로 구현되어 있기 때문입니다.
이러한 특징은 다중 스레드(Multi-Thread) 환경에서 더 효율적인 성능을 보입니다. 정말 그러한지 실제로 테스트를 해봅시다.
import java.util.Collections;
import java.util.HashMap;
import java.util.Hashtable;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
import java.util.stream.IntStream;
/**
* Hashtable, ConcurrentHashMap
* SynchronizedMap 의 성능테스트
*
* @author kimtaeng
* created on 2018. 4. 16.
*/
class MadPlay {
private final static int MAX_THREAD_POOL_SIZE = 5;
private final static int MAX_TEST_COUNT = 5;
private final static int MAX_OPERATE_COUNT = 100000;
public static Map<String, Integer> testHashtable = null;
public static Map<String, Integer> testSyncMap = null;
public static Map<String, Integer> testConcMap = null;
public static void collectionPerformTest() throws InterruptedException {
testHashtable = new Hashtable<>();
runSomethingTest(testHashtable);
testConcMap = new ConcurrentHashMap<>();
runSomethingTest(testConcMap);
testSyncMap = Collections.synchronizedMap(new HashMap<>());
runSomethingTest(testSyncMap);
}
public static void runSomethingTest(final Map<String, Integer> testTarget) throws InterruptedException {
System.out.println("Target Class : " + testTarget.getClass());
long testAverageTime = 0L;
for (int testCount = 0; testCount < MAX_TEST_COUNT; testCount++) {
long testStartTime = System.nanoTime(); // 카운트 시작
ExecutorService testExecutor = Executors.newFixedThreadPool(MAX_THREAD_POOL_SIZE);
// rangeClosed 는 마지막 값을 포함하여 Looping
IntStream.range(0, MAX_THREAD_POOL_SIZE).forEach(count -> testExecutor.execute(() -> {
// random value를 put하는 액션 수행
for (int opCount = 0; opCount < MAX_OPERATE_COUNT; opCount++) {
Integer randomValue = (int) Math.ceil(Math.random() * MAX_OPERATE_COUNT);
testTarget.put(String.valueOf(randomValue), randomValue);
}
}));
// 수행 종료. 이미 수행중인 것은 마저 진행하지만 새 작업은 허용하지 않는다.
testExecutor.shutdown();
// shutdown 이후에 모든 작업이 종료되기까지 대기한다.
testExecutor.awaitTermination(Long.MAX_VALUE, TimeUnit.DAYS);
long testEndTime = System.nanoTime(); // 카운트 끝
long testTotalTime = (testEndTime - testStartTime) / 1000000L;
testAverageTime += testTotalTime;
System.out.println(testTarget.getClass() + "'s Test " + (testCount + 1) + ": " + testTotalTime);
}
System.out.println(testTarget.getClass() + "'s average time is " + testAverageTime + "\n");
}
public static void main(String[] args) throws InterruptedException {
collectionPerformTest();
}
}
위와 같이 다중스레드 환경에서 Hashtable, ConcurrentHashMap, SynchronizedMap의 성능테스트를 위한 코드는 준비되었습니다. 이제 실행만 시키면 되는데요. 위 코드를 복사하여 IDE에서 직접 수행해도 그대로 동작이 될겁니다.
단 JDK 8 이상이어야 해요. 만일 이하 버전을 사용하신다면 IntStream 부분을 for문으로, ExecutorService를 실행시키는 excute메서드 부분과 forEach 내부 코드를 for문으로 변경하면 됩니다.
코드의 실행 결과는 아래와 같습니다.
Target Class : class java.util.Hashtable
class java.util.Hashtable's Test 1: 426ms
class java.util.Hashtable's Test 2: 415ms
class java.util.Hashtable's Test 3: 167ms
class java.util.Hashtable's Test 4: 234ms
class java.util.Hashtable's Test 5: 162ms
class java.util.Hashtable's average time is 1404ms
Target Class : class java.util.concurrent.ConcurrentHashMap
class java.util.concurrent.ConcurrentHashMap's Test 1: 222ms
class java.util.concurrent.ConcurrentHashMap's Test 2: 133ms
class java.util.concurrent.ConcurrentHashMap's Test 3: 60ms
class java.util.concurrent.ConcurrentHashMap's Test 4: 93ms
class java.util.concurrent.ConcurrentHashMap's Test 5: 65ms
class java.util.concurrent.ConcurrentHashMap's average time is 573ms
Target Class : class java.util.Collections$SynchronizedMap
class java.util.Collections$SynchronizedMap's Test 1: 309ms
class java.util.Collections$SynchronizedMap's Test 2: 204ms
class java.util.Collections$SynchronizedMap's Test 3: 271ms
class java.util.Collections$SynchronizedMap's Test 4: 193ms
class java.util.Collections$SynchronizedMap's Test 5: 256ms
class java.util.Collections$SynchronizedMap's average time is 1233ms
직접 코드를 수행하니까 속도의 차이가 보입니다.
끝으로 정리해보면
- List Interface
- ArrayList : 상대적으로 빠르고 요소에 대해 순차적으로 접근할 수 있다.
- Vector : ArrayList의 이전 버전이며 모든 메서드가 동기화 되어 있다.
- LinkedList : 순서가 변경되는 경우 노드 링크만 변경하면 되므로 삽입, 삭제가 빈번할 때 빠르다.
- Set Interface
- HashSet : 빠른 접근 속도를 가지고 있으나 순서를 예측할 수 없다.
- LinkedHashSet : 요소가 추가된 순서대로 접근할 수 있다.
- TreeSet : 요소들의 정렬 방법을 직접 지정할 수 있다.
- Map Interface
- HashMap : 중복을 허용하지 않고 순서를 보장하지 않으며 null 값을 허용한다.
- Hashtable : HashMap 보다는 느리지만 동기화를 지원하며 null 값을 허용하지 않는다.
- TreeMap : 정렬된 순서대로 Key와 Value를 저장하므로 빠른 검색이 가능하지만 요소를 추가할 때 정렬로 인해 오래걸린다.
- LinkedHashMap : HashMap과 기본적으로 동일하지만 입력한 순서대로 접근이 가능하다.