Anchor the Project Context First
When you first open Claude Code, the possibilities seem endless. It can read your repository, edit files, and run tests. But after a few sessions, you start noticing a pattern in the mistakes. It confuses build commands, runs tests too broadly, and suggests code styles your team has already rejected. This is less about model capability and more about starting without a baseline for the project.
/init is the fastest built-in command to create that baseline. It analyzes the project immediately and generates a CLAUDE.md file
containing the core rules. From that point on, Claude Code reads this file first whenever a new session starts, picking up the project context automatically.
If consistency across sessions matters more than getting one conversation right, this is the first thing worth setting up.
As of October 4, 2025, the official Anthropic documentation describes
/initas the default slash command for initializing theCLAUDE.mdguide. Project memory can live in./CLAUDE.mdor./.claude/CLAUDE.md, and the docs recommend including build, test, and lint commands along with code style and architecture patterns.
What /init Creates Is a Baseline, Not Just a File
The output of /init is a single Markdown file, but the actual impact goes beyond that.
It establishes a consistent lens through which Claude Code reads the same project at the start of every session.
Codebase Scan and Context Extraction
When you run /init, Claude Code quickly scans the directory structure, key configuration files
(package.json, build.gradle, requirements.txt), and major documentation.
It then summarizes the language, framework, test runner, and architecture patterns into CLAUDE.md.
However, every team has different default commands and boundaries. Details like whether ./gradlew test is the standard command,
whether integration tests should never run locally, or how the team handles DTO conventions only surface late from reading code alone.
That is why the official docs also recommend putting frequently used commands and rules directly into CLAUDE.md.
For example, if you work on an order service repository, adding just the following to the generated file noticeably changes the direction of the first response.
# Build and test
- build: ./gradlew assemble
- unit test: ./gradlew test
- Do not run integration tests locally
# Conventions
- Do not change public API specs without approval
- Use `data class` for Kotlin DTOs
- Place new business rules in the `OrderPolicy` layer
# Read first
- @README.md
- @docs/architecture/order-flow.md
With this file in place, Claude Code checks OrderPolicy first, avoids running heavy tests locally,
and does not waste the early part of a session hunting for the README.
Upfront Token Investment and Prompt Caching
Running /init consumes thousands to tens of thousands of tokens in a single pass, depending on the size and complexity of the codebase.
Scanning and summarizing the entire project does come with a noticeable upfront cost.
When I tested /init on this blog project, the cumulative usage shown by /context was roughly 20,000 tokens.
The system prompt accounted for about 5-6k, system tools for about 8-9k, and messages for about 6k.
That said, the exploration tokens consumed internally during the /init process may be tallied separately,
so these numbers alone do not represent the full cost. The key takeaway is that there is a real initial investment.
Still, from a usage perspective, this investment pays for itself quickly. The completed CLAUDE.md is automatically injected
as part of the system prompt every time a new session opens.
At this point, Anthropic’s Prompt Caching kicks in, and the repeatedly injected project context triggers cache hits.
The result: the tens of thousands of “discovery cost” tokens previously spent re-exploring the repository from scratch disappear, replaced by much cheaper cached tokens that deliver faster and more consistent responses.
Starting Without /init Accumulates Hidden Costs
You can work without /init. But you end up re-explaining the same things every session,
and the direction of responses drifts slightly each time.
This cost grows fast, especially in large repositories or monorepo-like setups.
The three most common repetitions are: re-specifying which commands to use for verification, re-orienting where to start reading, and re-correcting output formats your team dislikes. Each one looks like a minor inconvenience in isolation, but as these round trips pile up, uncached input tokens keep accumulating and your focus erodes faster than your token budget.
Degraded First-Response Quality and Correction Overhead
/init proves especially valuable when “first-response quality” matters. Tasks like root-cause analysis for bugs,
minimal fix proposals, or organizing review comments all share a common trait:
if the initial direction is off, every subsequent exchange turns into correction overhead.
With CLAUDE.md in place, Claude Code already knows the project’s boundaries and priorities from the start,
making it easier to skip the “search broadly, then narrow down” exploration pattern.
/init Alone Is Not Enough
Running /init first does not automatically produce good context. If CLAUDE.md becomes stale,
Claude Code trusts outdated commands as-is. If it grows too verbose, important rules get buried.
When session quality remains inconsistent despite having the file, the issue usually is not that /init fell short
but that the memory content has become inaccurate or bloated.
Security also requires some thought. Avoid putting API keys, production URLs, or personal sandbox details
into a CLAUDE.md that you share with the team.
The official docs introduce personal memory (~/.claude/CLAUDE.md) and import syntax (@path/to/file) for exactly this reason.
Shared standards, personal preferences, and sensitive information are easier to manage when they do not mix in a single file.
Ultimately, what matters more than whether you run /init is first clarifying what the project needs Claude Code to always remember.
The official guide also recommends a workflow of: 1) extract baseline context with /init, 2) refine the generated CLAUDE.md
to match the team’s actual rules, and 3) then start the real work, rather than jumping straight into coding.
Just Run /init and Go
If you start looking for better Claude Code usage through elaborate prompts, fatigue sets in quickly.
What actually deserves attention first is the basic context you keep re-explaining every session.
/init is the smallest, most practical starting point for eliminating that repetition.
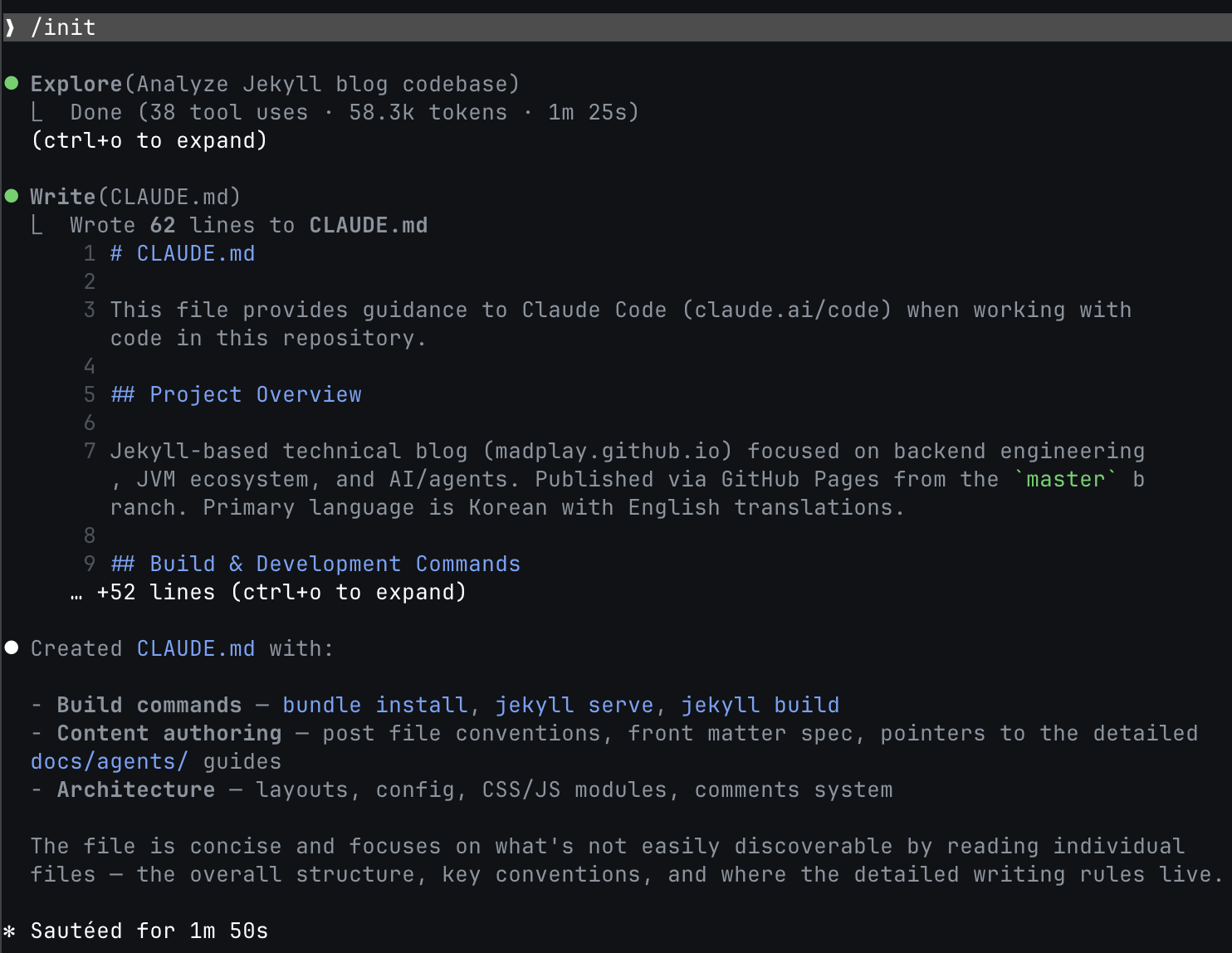
The image below shows the actual result of running /init on this blog project.
You can see the flow of scanning the codebase and generating CLAUDE.md,
along with an overview of the generated file in a single screen.
The sense that “what to read first” and “which commands to use by default” get locked in early is visible here.
The first couple of sessions, explaining things in conversation is fine.
But once you open a third session on the same project, anchoring the context before the model is generally the better move.
The reason to run /init first in Claude Code is not to get smarter answers immediately, but to ensure the next session starts from the same baseline.